MAT-427: Data Splitting + KNN
Regression: Conditional Averaging
Restaurant Outlets Profit dataset
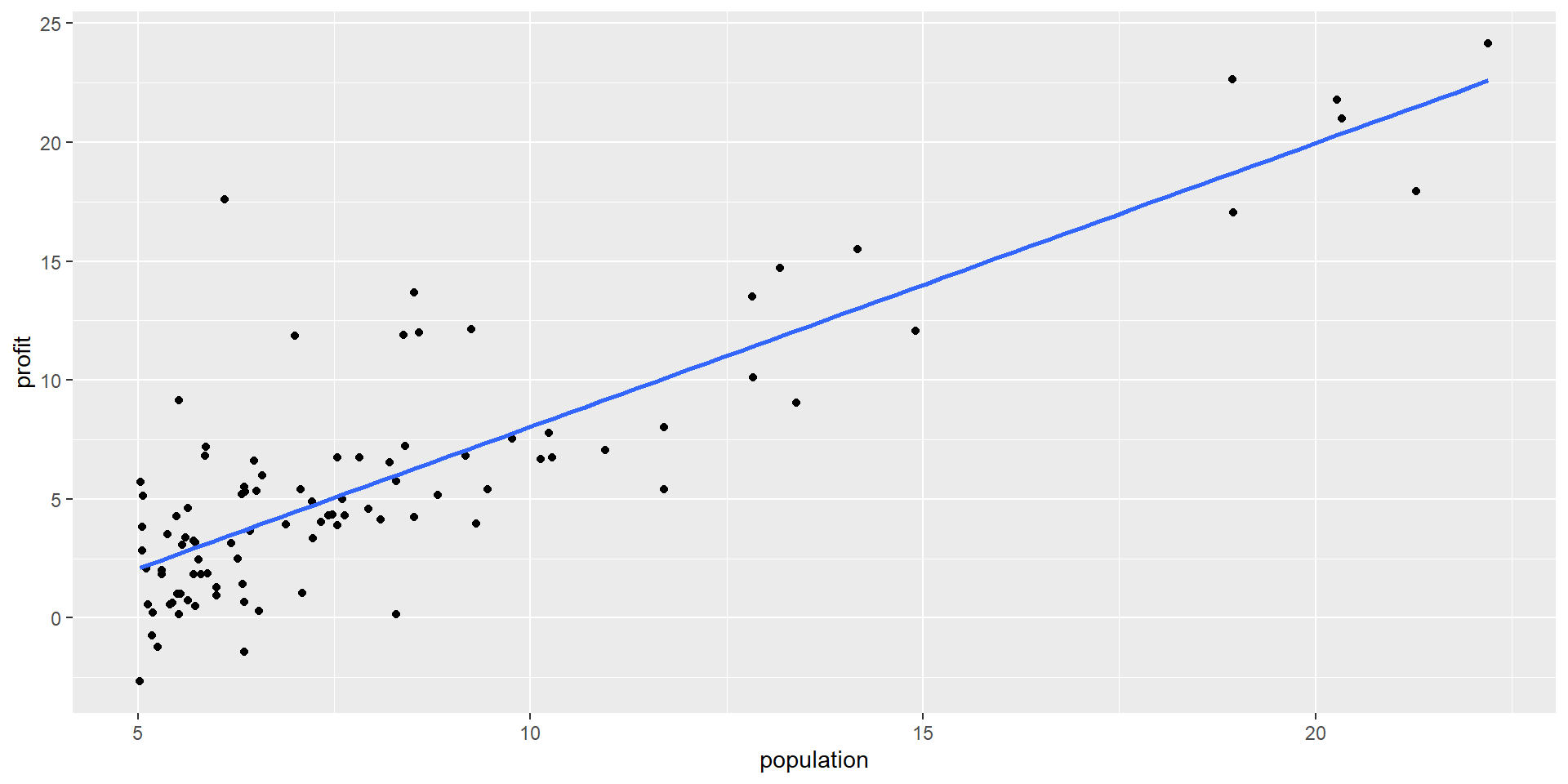
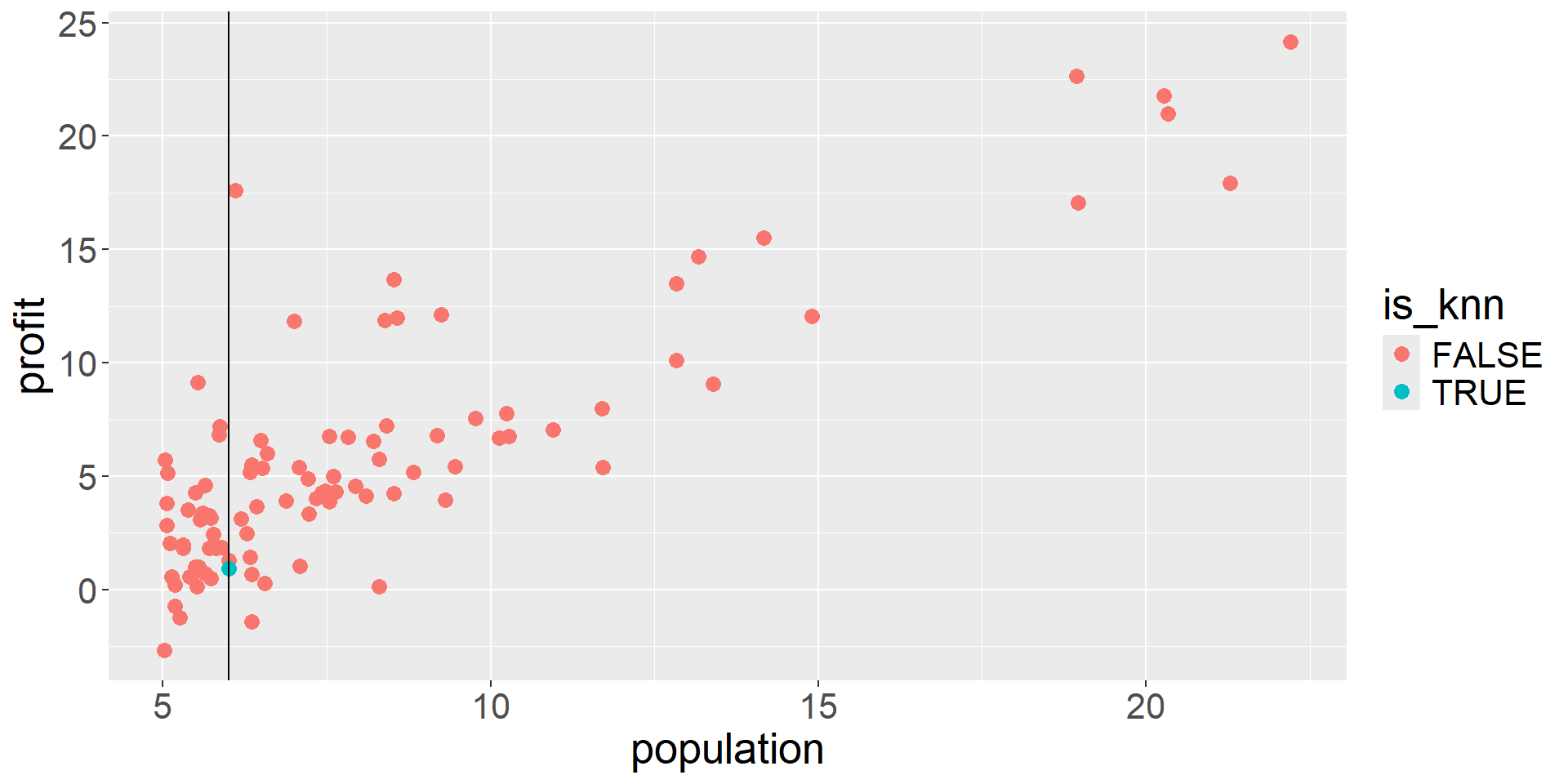
What is a good value of \(\hat{f}(x)\) (expected profit), say at \(x=6\)?
A possible choice is the average of the observed responses at \(x=6\). But we may not observe responses for certain \(x\) values.
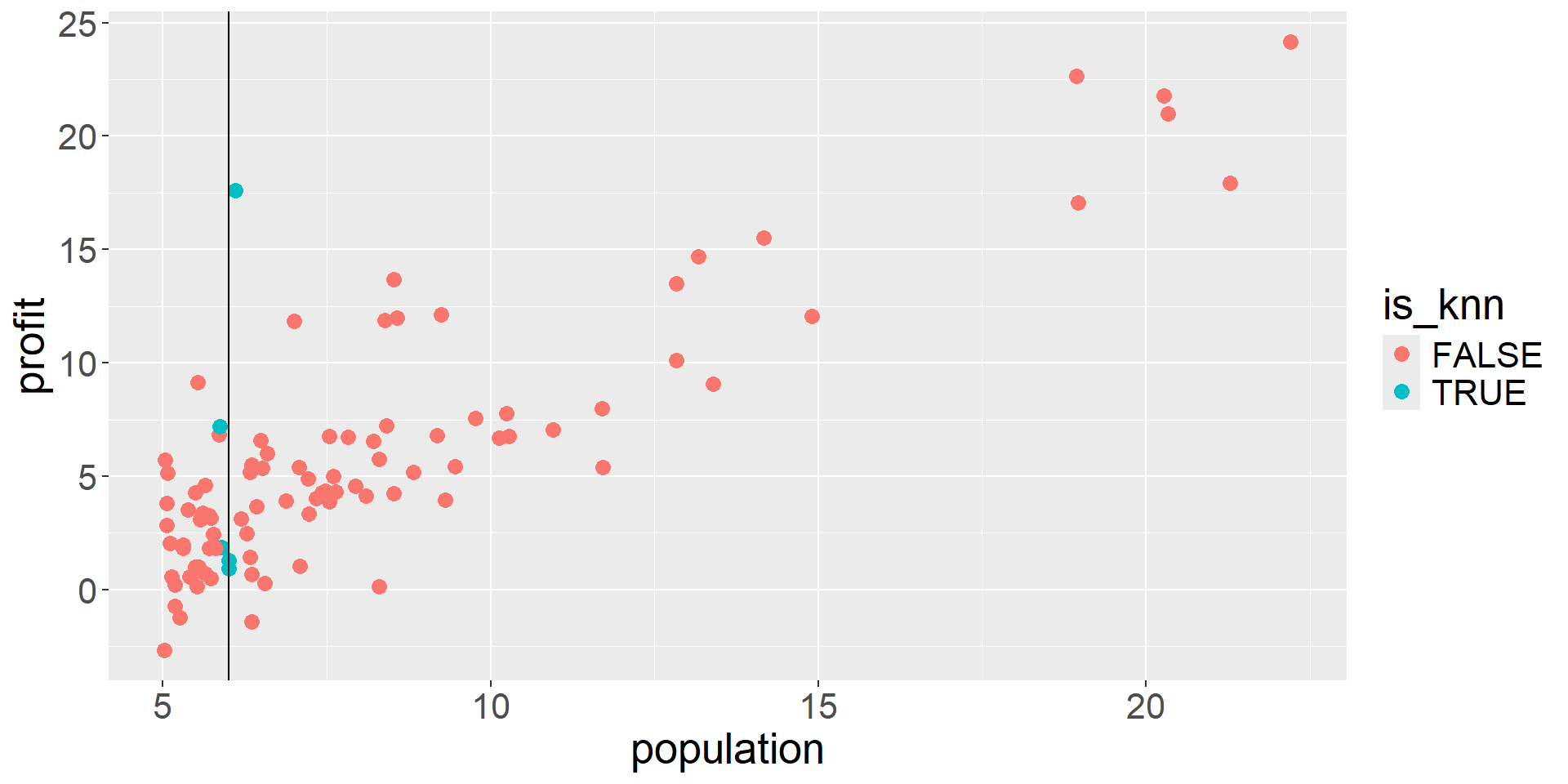
KNN Regression (single predictor): Fit
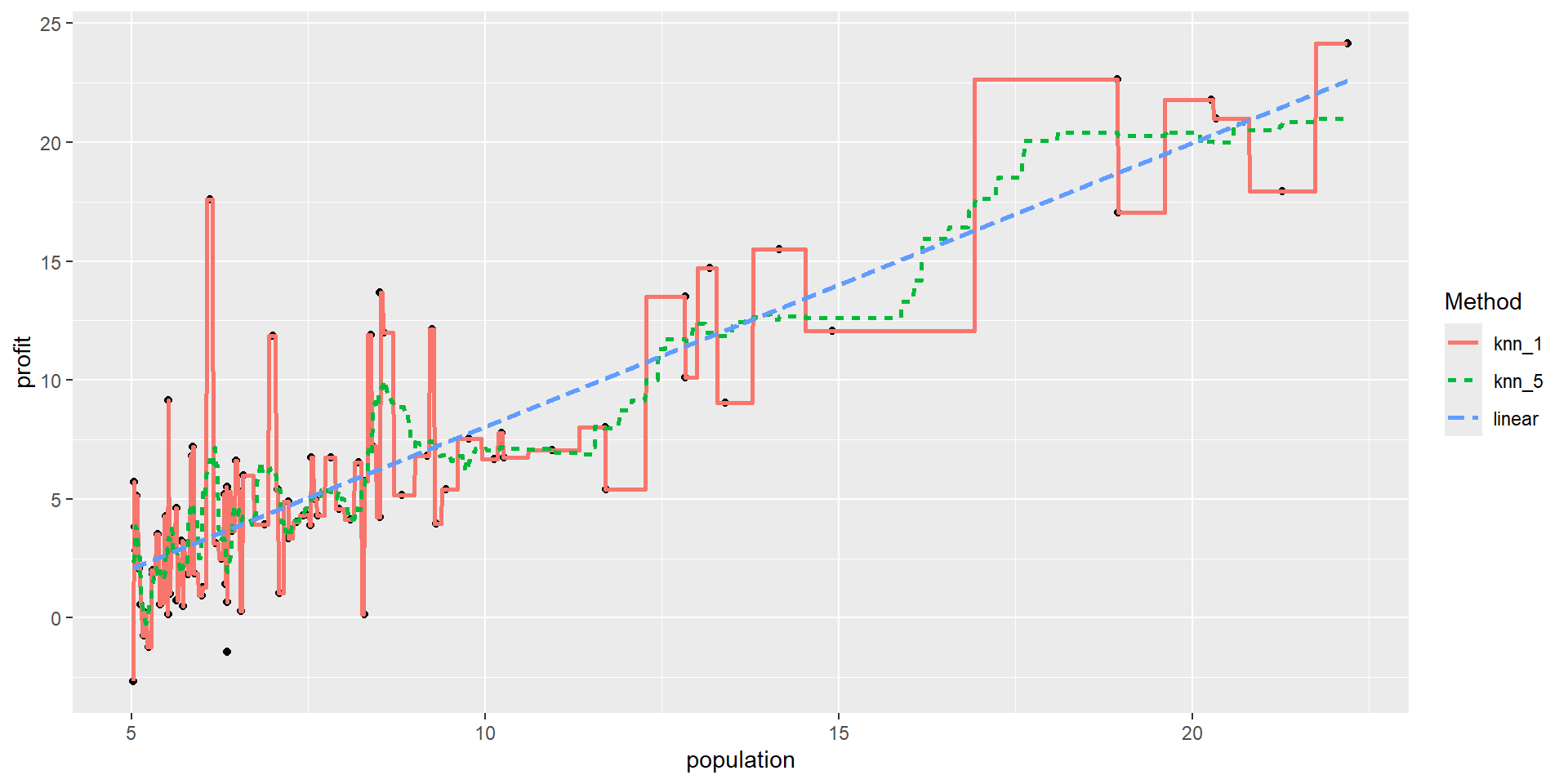
Regression Methods: Comparison
K-Nearest Neighbors Regression (multiple predictors)
- Test Point:
Gr_Liv_area= 2000 square feet, andBedroom_AbvGr= 3, then
# obtain 10-nn prediction
predict(knnfit10, new_data = tibble(size_scaled = (2000 - mean(ames_train$Gr_Liv_Area))/sd(ames_train$Gr_Liv_Area),
num_bedrooms_scaled = (3 - mean(ames_train$Bedroom_AbvGr))/sd(ames_train$Bedroom_AbvGr)))# A tibble: 1 × 1
.pred
<dbl>
1 256380![]()