MATH 427: Evaluating Classification Models
KNN: Confusion Matrix (Sexy)
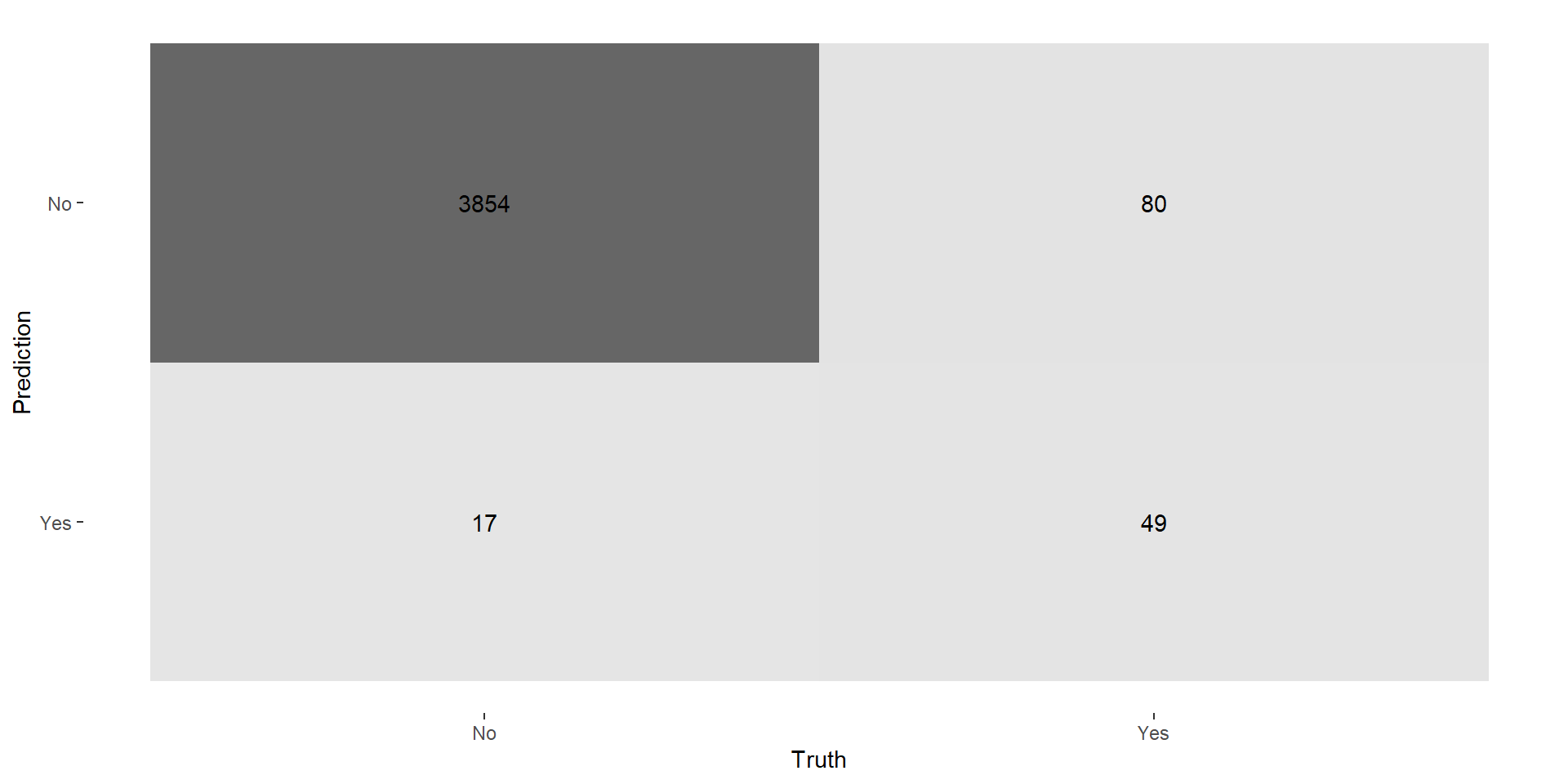
Logistic Regression: Confusion Matrix
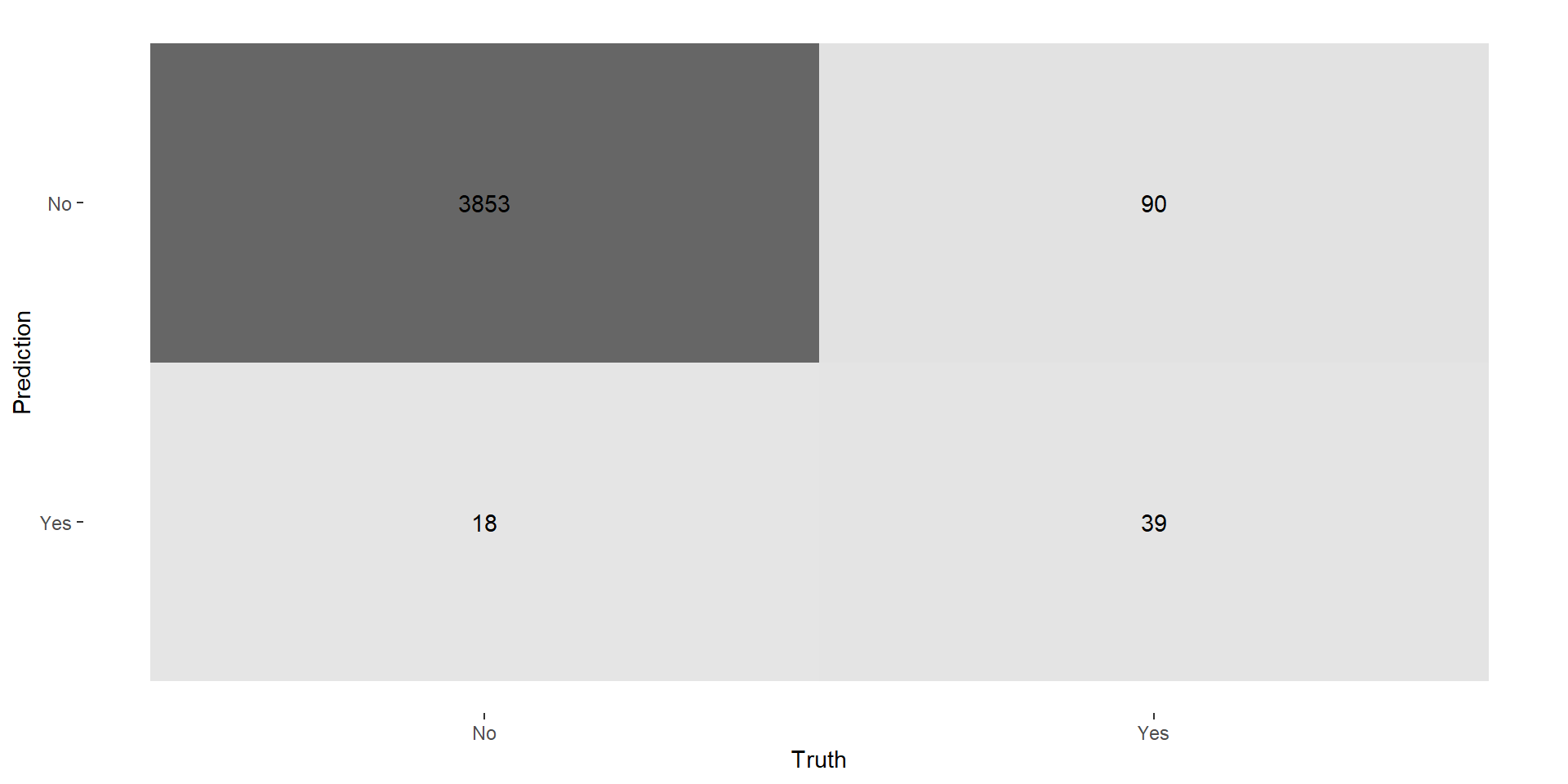
KNN: Performance
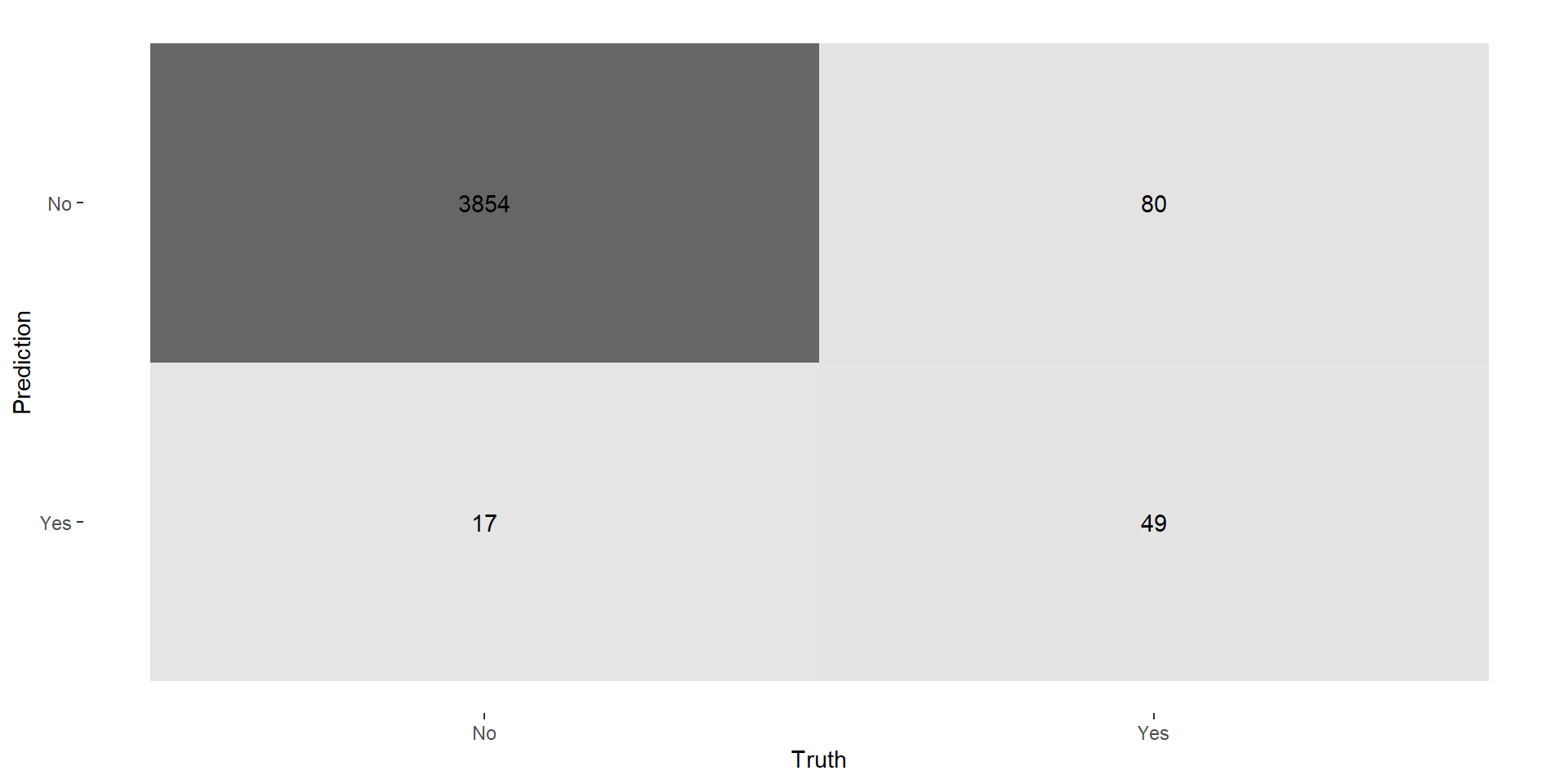
- Accuracy: \((3854+49)/4000 = .976 = 97.6\%\)
- Recall/Sensitivity: \(49/(49+80) = 0.380 = 38.0\%\)
- Precision/Positive Predictive Value (PPV): \(49/(49+17) = .742 = 74.2\%\)
- Specificity: \(3854/(3854+17) = 0.996 = 99.6\%\)
- Negative Predictive Value (NPV): \(3854/(3854+80) = 98.0\)
Logistic Regression: Performance
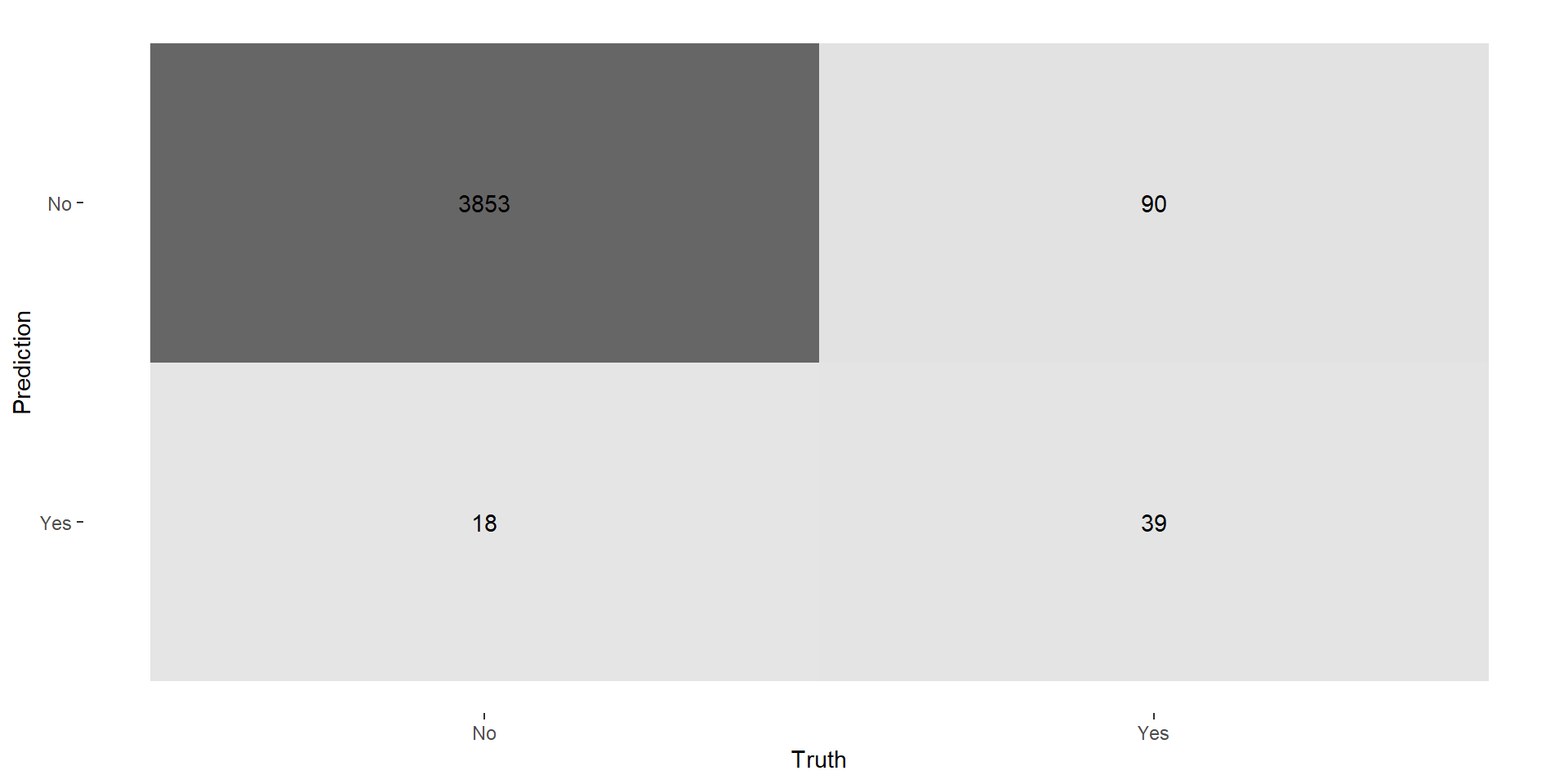
Discussion
- For each of the following metrics, brainstorm a situation in which that metric is probably the most important:
- Recall
- Precision
- Accuracy
![]()