MATH 427: Decision Trees
Terminology for Trees


Building a Tree and Prediction
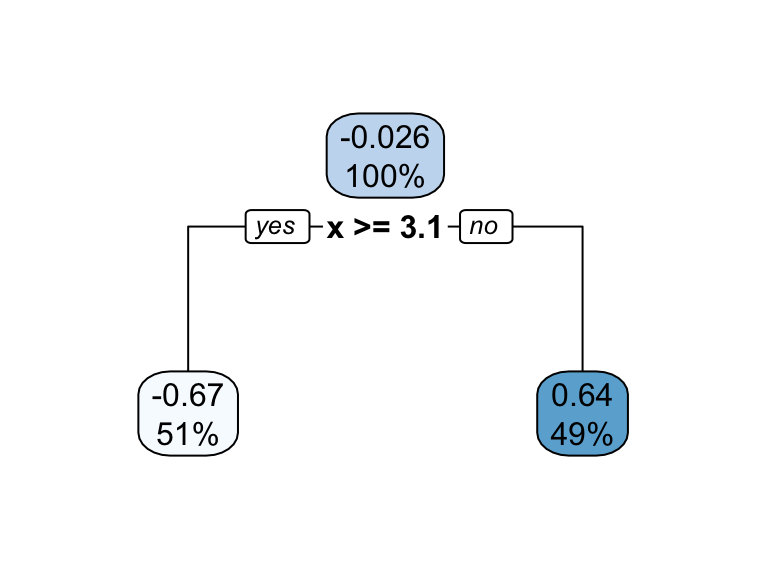
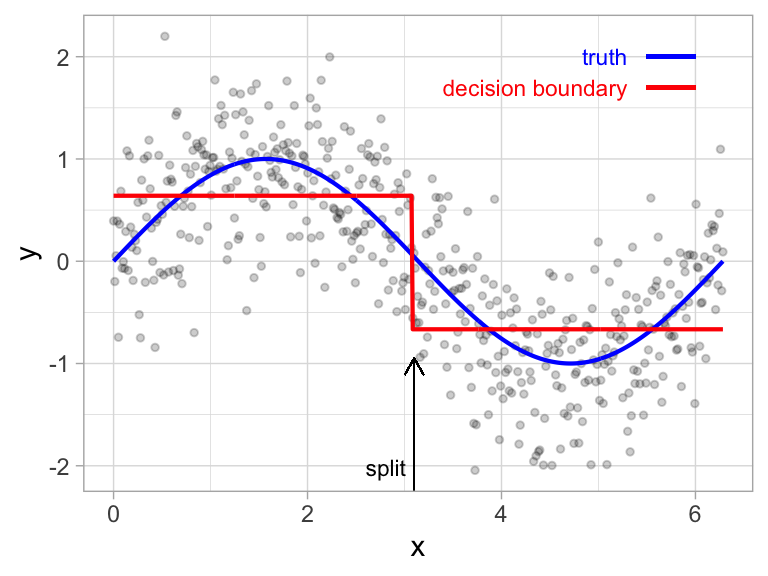
Building a Tree and Prediction
Building a Tree and Prediction

From ISLR
Overfitting
- This process described above is likely to overfit the data
- One solution: require each split to improve performance by some amount
- Bad Idea: sometimes seemingly meaningless cuts early on enable really good cuts later on
- Good solution: pruning
- Build big tree and the prune off branches that are unnecessary
![]()