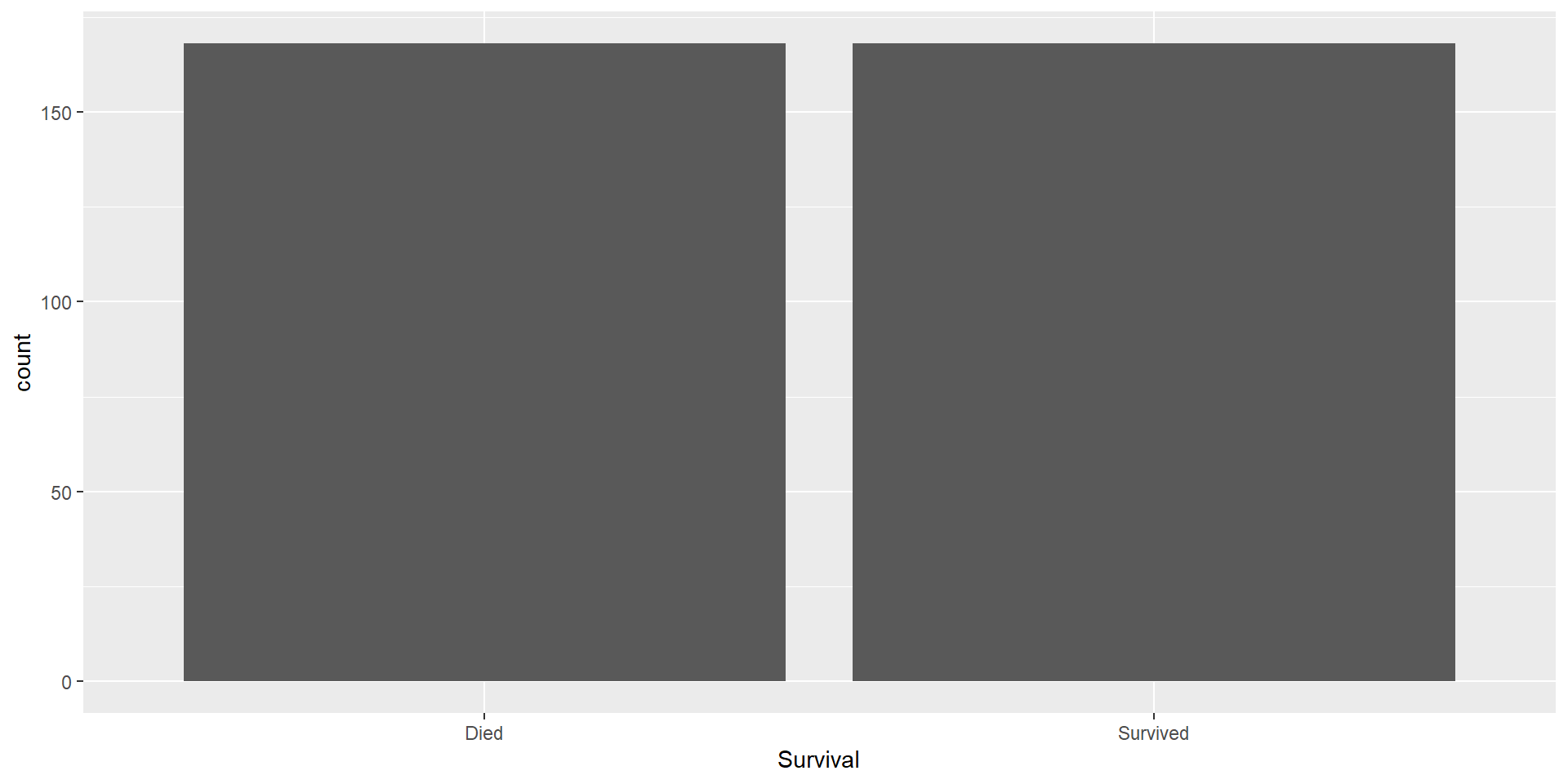
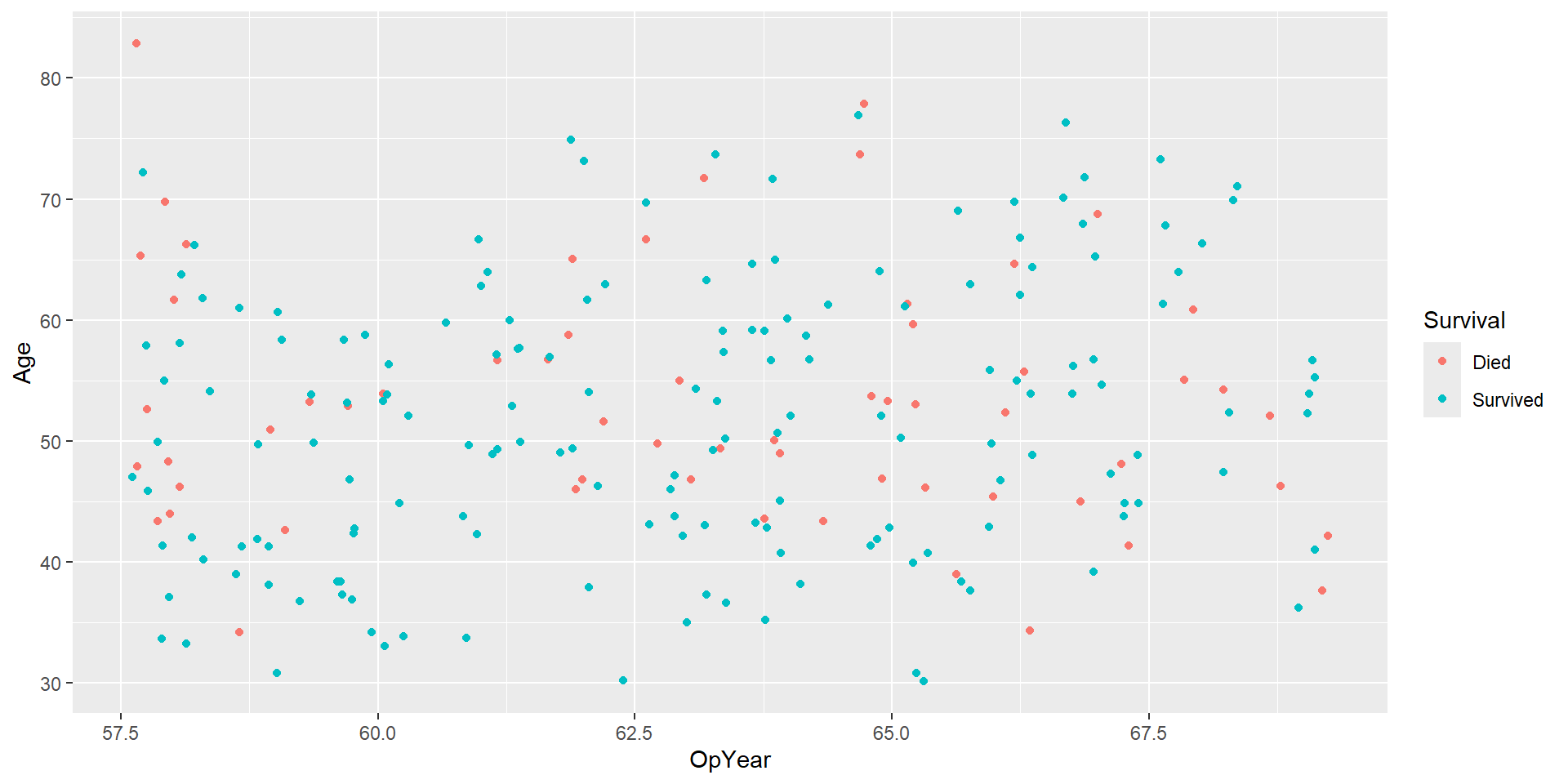
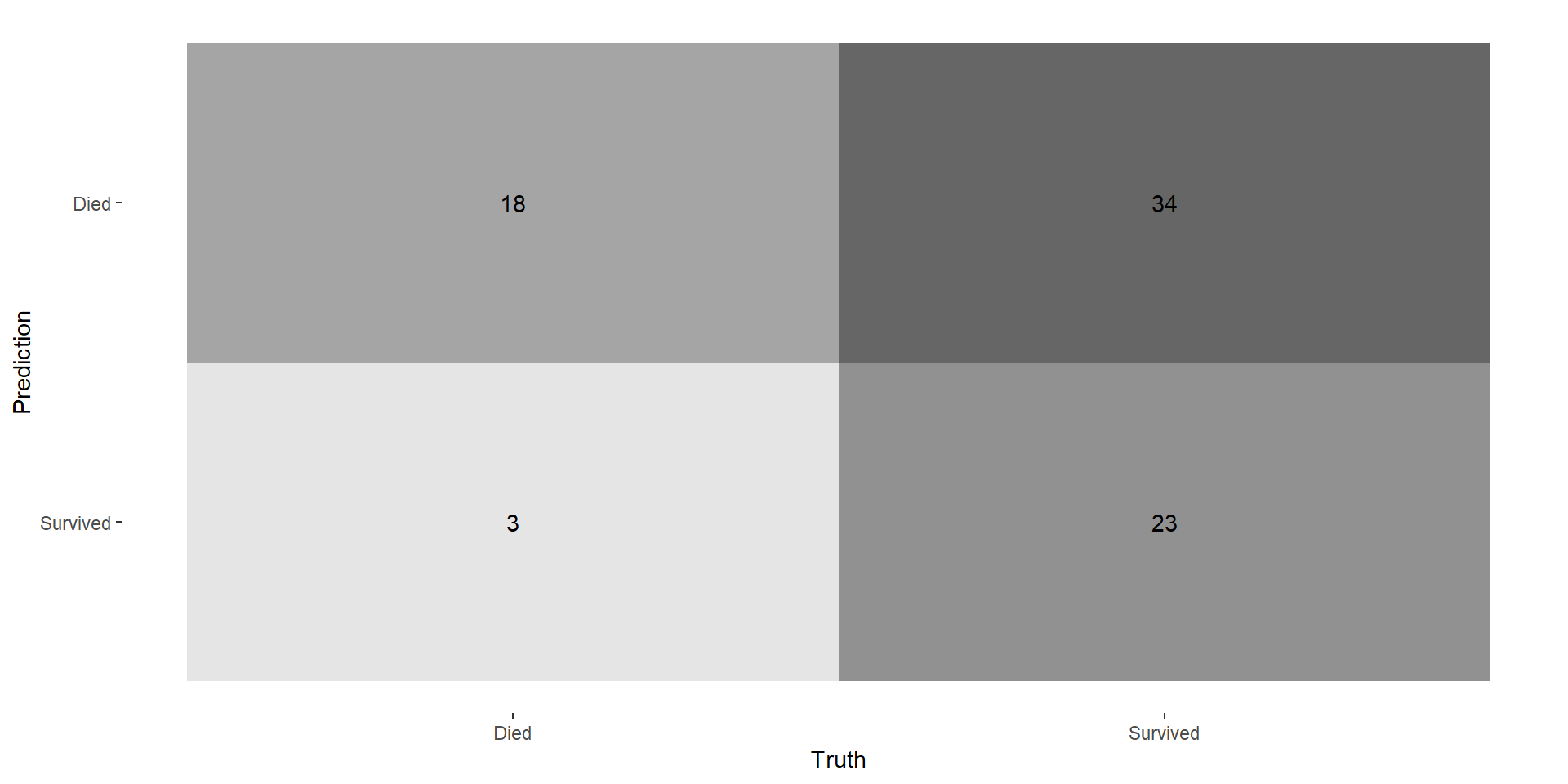Investigate how your performance metrics change between balanced data and unbalanced data
Additional Considerations:
Impact of boundaries/models?
Impact of sample size?
Impact of noise level?
Please write down observations so we can discuss
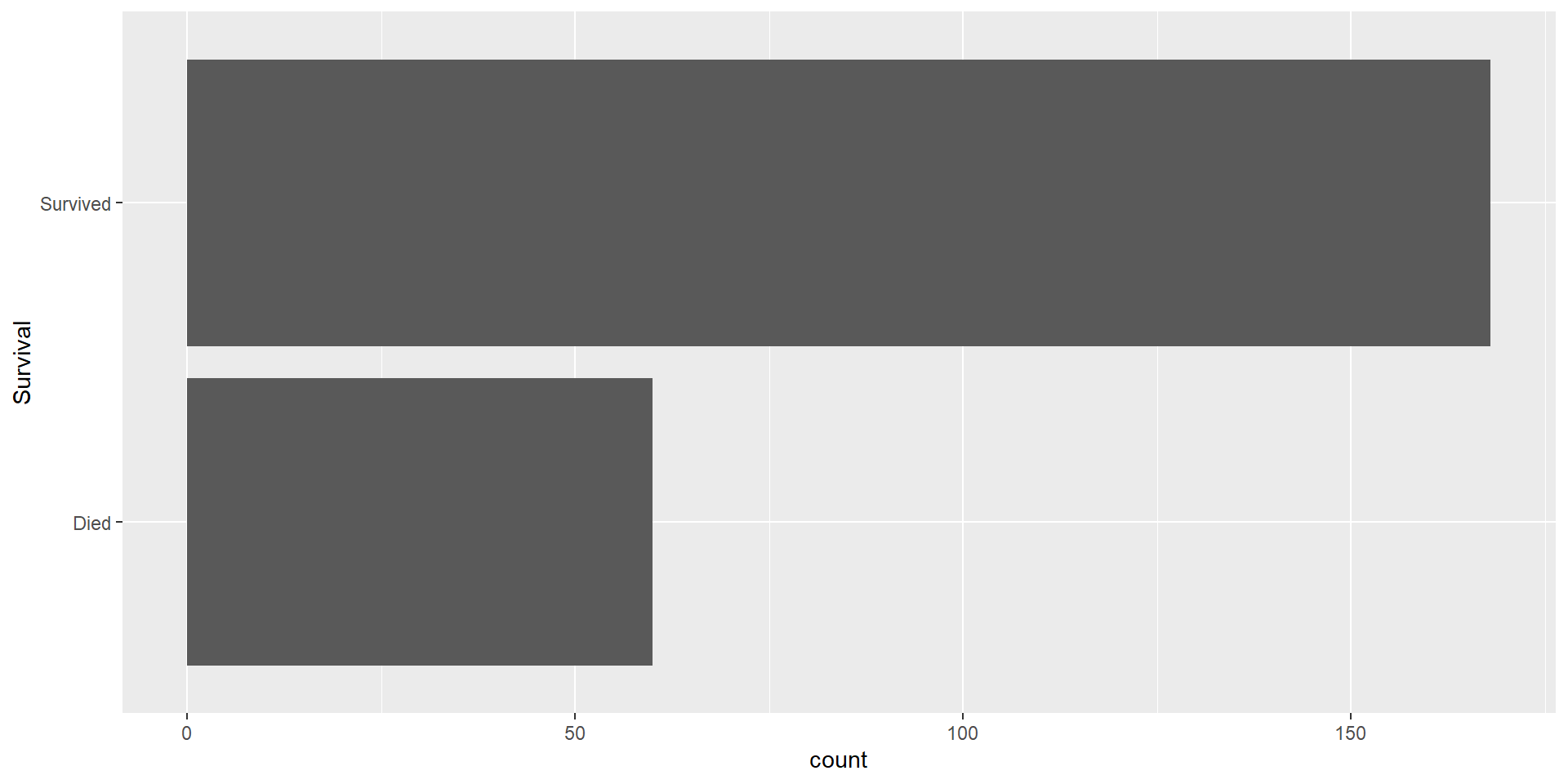
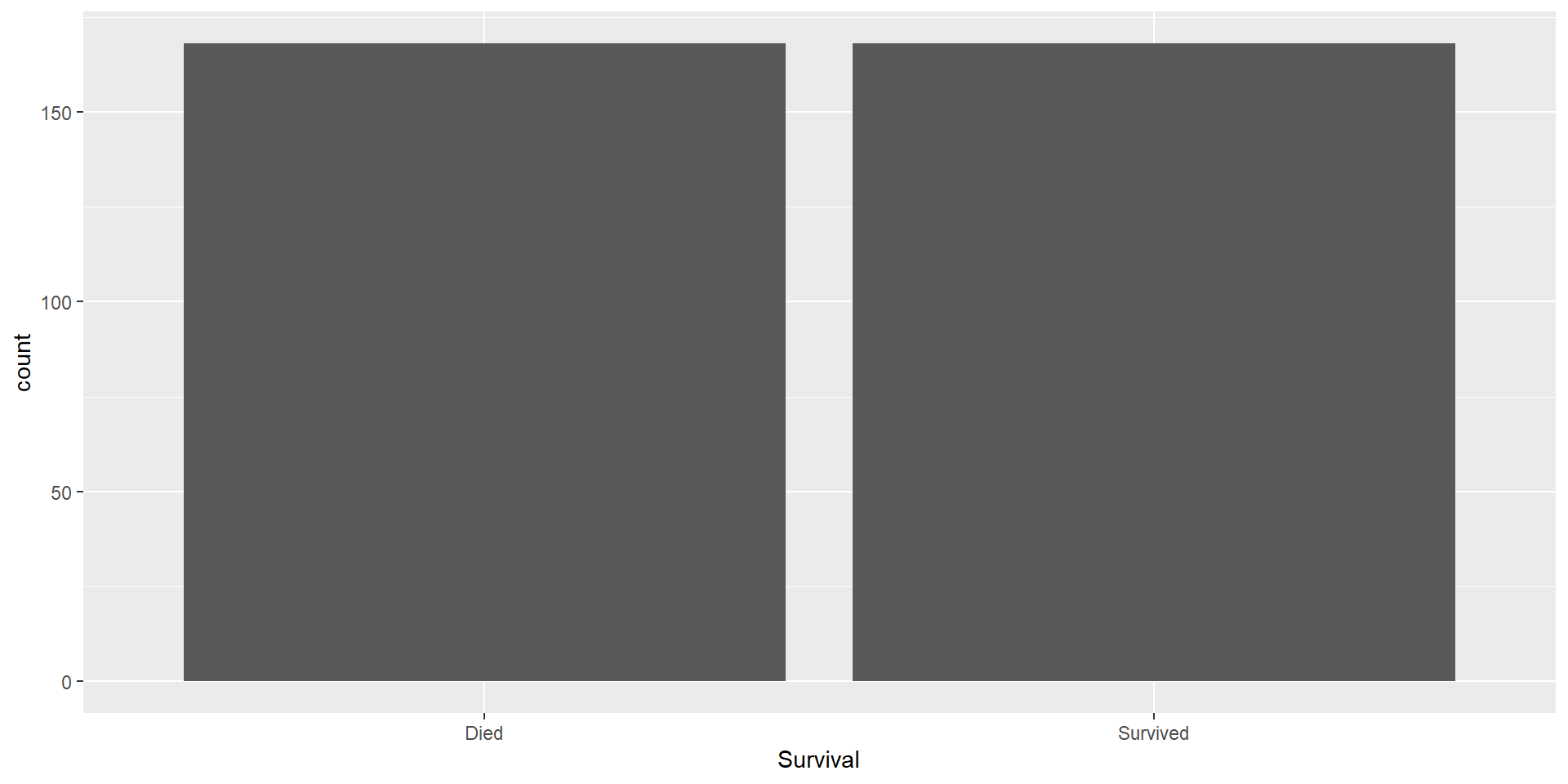
Dealing with Class-Imbalance
Class-Imbalance
Class-imbalance occurs where your the classes in your response greatly differ in terms of how common they are
Occurs frequently:
Medicine: survival/death
Admissions: enrollment/non-enrollment
Finance: repaid loan/defaulted
Tech: Clicked on ad/Didn’t click
Tech: Churn rate
Finance: Fraud
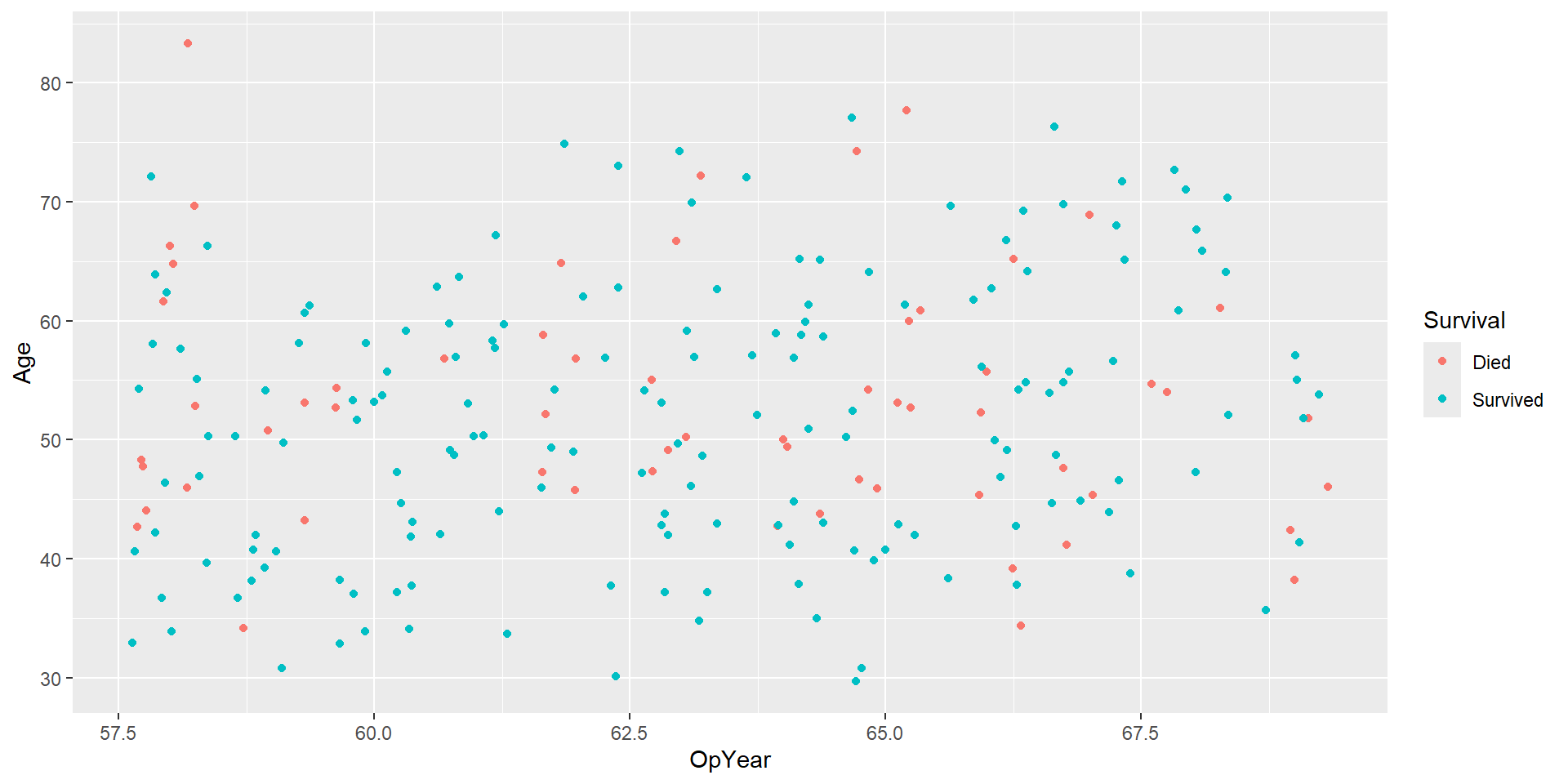
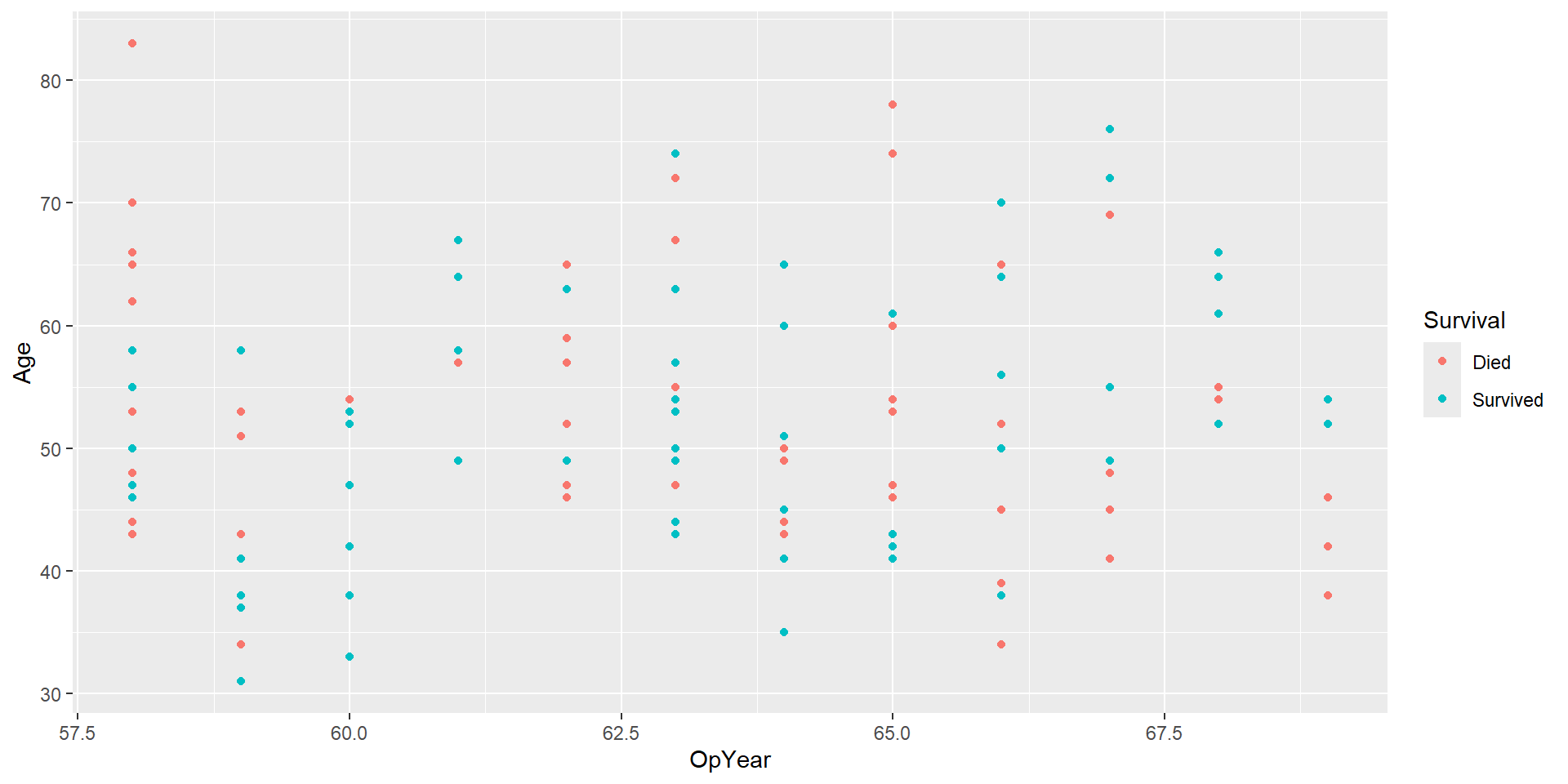
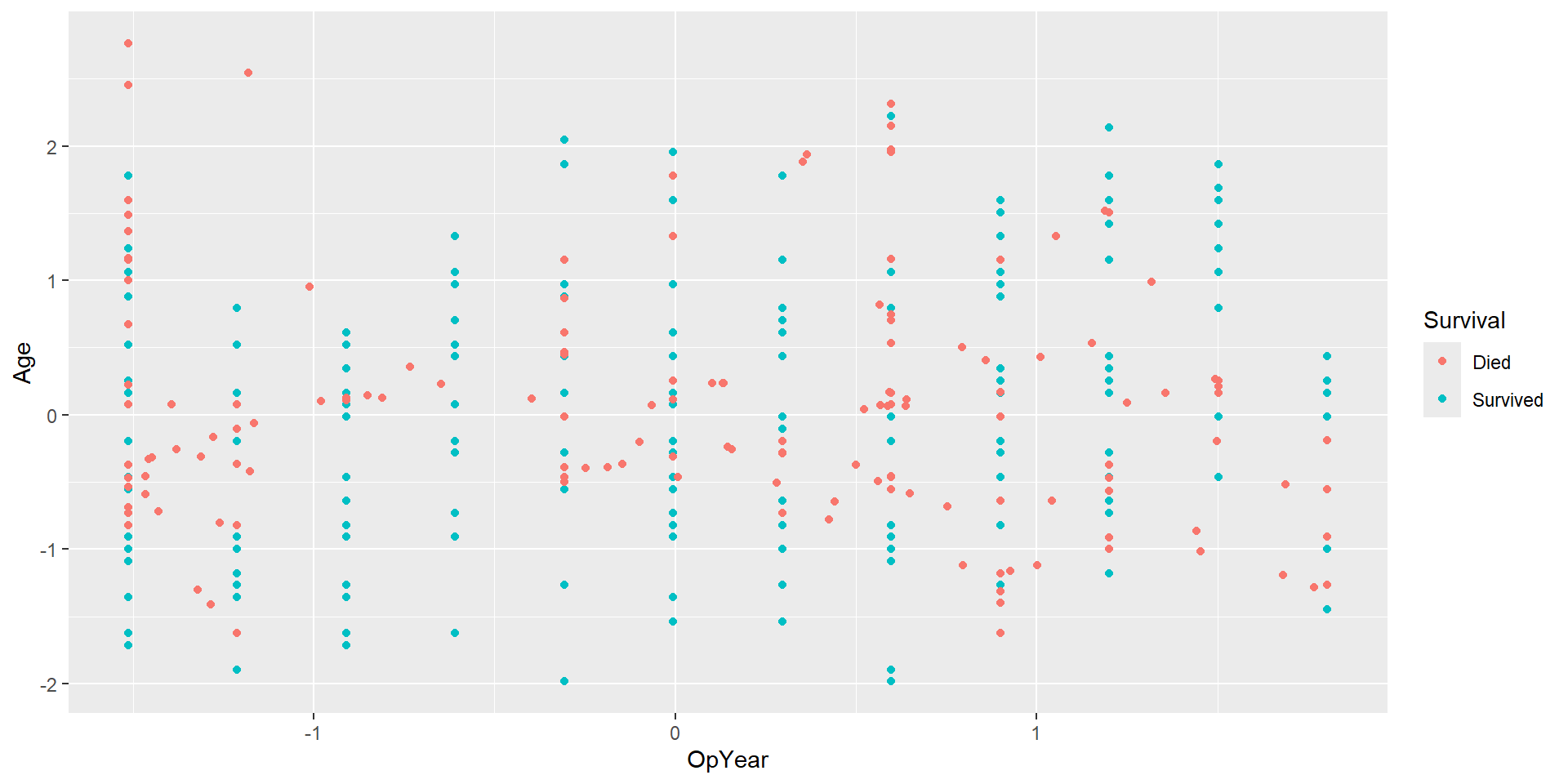
Data: haberman
Study conducted between 1958 and 1970 at the University of Chicago’s Billings Hospital on the survival of patients who had undergone surgery for breast cancer.
Goal: predict whether a patient survived after undergoing surgery for breast cancer.
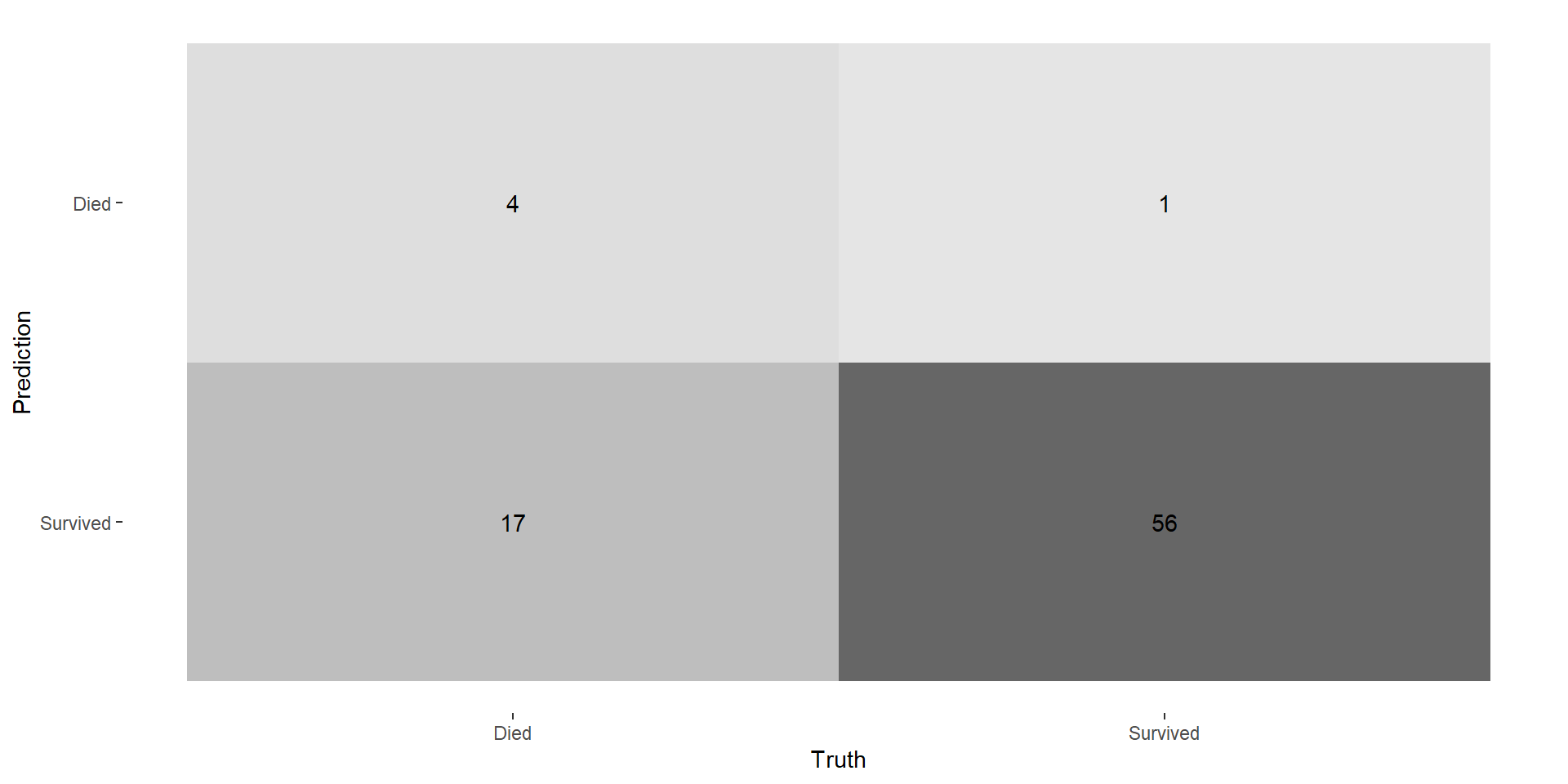
Usually, model predicts a probability, then you make a classification based on that probability
Choosing the best model probably means (1) calibrating your probabilities correctly, then (2) making classifications/decisions to optimze your use-case
Scoring Rules
Scoring rule: metric that evaluates probabilities
Notation:
\(\hat{p}_{ik}\): predicted probability observation \(i\) is in class \(k\)
\(y_{ik}\): 1 if observation \(i\) is in class \(k\), 0 otherwise